
Summary
To get CUDA 8.0 on Win 64bit up and running, download and install:
CUDA 8.0
Microsoft Visual Studio Community 2017 with Update 3 x64
Folllowing the testing directions at: http://linkevin.me/setting-up-cuda-in-windows-10-and-8-7/
Background
I've finally started dabbling in tensorflow, using the nicely explain python kernel for MNIST (the ability to recognize hand written digits 0-9) at Kaggle.com: https://www.kaggle.com/kakauandme/tensorflow-deep-nn
Using pycharm / anaconda in ubuntu 16.04 running in a VMware Player 12 on a slow celeron 3GB laptop, I kept hitting performance and then memory errors on the tf validation, manifesting itself as
training_accuracy / validation_accuracy => 0.96 / 0.98 for step 2499
starting validation
terminate called after throwing an instance of 'std::bad_alloc'
what(): std::bad_alloc
Process finished with exit code 134 (interrupted by signal 6: SIGABRT)
On my limited budget I recently bought a replacement workstation (my 10 year old trusty Dell XPS 410 w/ 3GB, Win 10 Pro) with a another used computer, an HP Z600 with 8GB, for 40000 yen ($350). Pulled the RAID disks out of the Dell and into the new workstation and it worked like a charm. I was pleasantly surprised that it came with a Nvidia Quadro 2000 GPU, which if I bought new would cost more than the used pc it came in. What a great deal.
Installing CUDA
After updating my graphics driver and rebooting, I downloaded the CUDA 1.2GB install (cuda_8.0.61_win10.exe) and patch. Halfway through the install it showed this message:
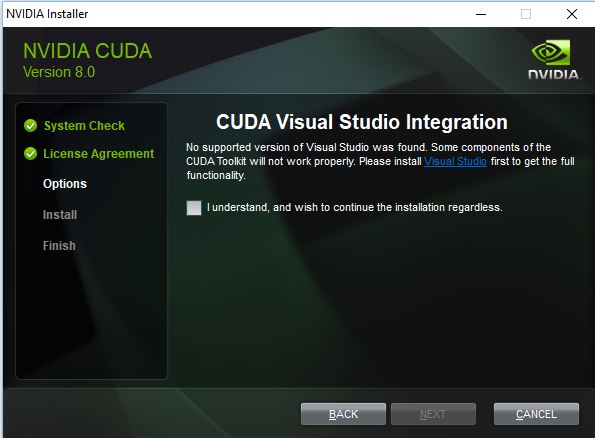
Conveniently the link goes to visual studio and even better there is a community edition. I cancelled the CUDA install, and installed Visual Studio 2017 Community Edition. VS is massive with lots of options. I ended installing the Universal Windows Platform development and the Desktop Development with C++ as I figured that would get the C++ libraries that I needed. Installed, rebooted.
Again I tried the CUDA install. Again the same notification that VS was not installed. I decided to troubleshoot later and finished the install.
There is a nice tutorial to see if your CUDA is up and running: http://linkevin.me/setting-up-cuda-in-windows-10-and-8-7/
Following those steps I could see in his screenshot that I was not only missing the CUDA in Visual Studio, but also the VS templates. Doing some more googling, I found this page:
http://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
which shows VS 2015 as the supported version for CUDA 8.0. Download a older VS requires a free subscription to Microsoft's developer program. I uninstalled VS 2017, and installed VS Community 2015 with Update 3. That generated this message:
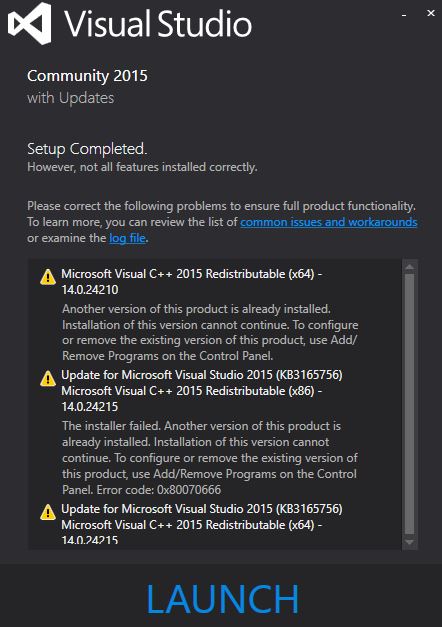
I'm not sure yet how important this is for CUDA.
Testing
Back to http://linkevin.me/setting-up-cuda-in-windows-10-and-8-7/
Creating a CUDA project, I get this error message:
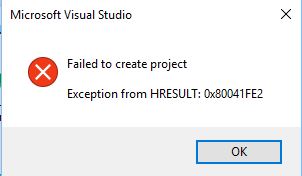
So apparently a common problem: https://devtalk.nvidia.com/default/topic/969988/unable-to-create-project-in-cuda-8-0-and-visual-studio-community-2015/
With an easy solution (courtesy of Dydzej from the above link):
I had the same problem and I solved it by installing "Visual C++ 2015 Tools for Windows Desktop".
Visual studio 2015 does not support for C++ by default, so you have to go to projects Visual C++ and click on "Install Visual C++ 2015 Tools for Windows Desktop".Posted 11/17/2016 07:52 PM
The default program was slightly different that mentioned in the example.
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
When running it, the following output is produced:
{1,2,3,4,5} + {10,20,30,40,50} = {11,22,33,44,55}
Press any key to continue . . .